”It’s not DNS.”
"There’s no way it’s DNS”
”It was DNS.”
It’s as old as the internet. My age, basically.
For most people, DNS is like electricity. We don’t celebrate its very existence. We just moan and complain when it’s mysteriously absent for even a second. Such first world problems are met with less and less attention at the core, it seems, to get it right.
However, this is where we (ADAMnetworks) live. We protect people. Part of that protection is the emotion and disruption that happens when this stuff doesn’t work.
Let’s take a step back. In the DNS world, the original design was about recursing right back to the root servers if, and when needed.
Since most end users didn’t have recursive resolvers of their own, it became a standard that is in place to this day: ISPs stand up caching recursive DNS servers for their subscriber base to use. One dynamic that we witnessed at the onset of ubiquitous connectivity and the rise of social media was nation-state level disruption where ISPs were required to selectively block DNS queries to social media platforms, which gave rise to Google Public DNS (8.8.8.8/8.8.4.4), and while that was a very temporary route around the blockage, it served as good marketing for fast, anycast DNS servers, and now every sysadmin defaults to one of these centralized non-ISP DNS servers.

As the internet grew in scale and we saw a healthy tension between not-for-profit and for-profit enterprise, we saw this space evolve. See DNS encryption, for example:
Root DNS servers do not, and will not offer DoT, DoH or DoQ as their official statement states.
And yet, every commercially-operated “Protective DNS Resolver”, including those that are free to use, offer DNS encryption of one form or another.
Back to the purpose of this article: DNS resilience. The healthy tension described above is what has us thinking about the best approach to making sure DNS is resilient all of the time for the people we love.
Ideally, we can keep working in any of these scenarios:
- internal networking problems with DNS
- internal networking issues with a gateway
- ISPx internal disruptions
- Network transit issues within peering arrangements (including BGP disruptions)
- Upstream Protective Resolver reachability outages
None of these issues are addressed with one silver bullet, but a proven approach to the bulk of these issues can be addressed with these redundancies:
- high availability of a gateway
- high availability of endpoint-referenced DNS servers (but not by having two DNS servers used at an endpoint)
- High availability of Active Directory DNS servers (not to be confused with the prior bullet)
A lot of these resilience efforts are within the control of the enterprise or outsourced technology partner. However, what if your DNS supply chain is attacked?
- Public resolvers in use are down (say your ISP dropped the BGP route to your chosen resolvers)
- Your main ISP is experiencing total failure
The approach is to ensure there isn’t a single point of failure anywhere at any time. Let’s use the character trait of the original internet design, to be able to route around any obstacle to ensure there’s redundancy everywhere. To that end, here’s a simple checklist you can use as an audit, if everything works correctly, including a mature bug-free DNS resolver environment. We have taken the liberty of allocating a thoughtful weighting of points per check:
| Audit check | Answer | Yes Value |
|---|---|---|
| 1 Endpoints’ assigned DNS server offers High Availability | Yes/No | 30% |
| 2 Active Directory domain answers are available from multiple AD DNS servers | Yes/No | 25% |
| 3 Multiple resolver sets are used with DNSharmony | Yes/No | 25% |
| 4 Multiple ISPs via separate circuits | Yes/No | 10% |
| 5 Resolver pairs are split between ISP connections for best resilience | Yes/No | 10% |
| Max: | 100% |
Let’s dive into each of the above with more detail and examples:
Endpoints’ assigned DNS server offers High Availability
The syntax used in many networks is to use the last octet as a way of identifying the real vs virtual hosts for a typical /24 network:
10.128.1.1 is NODE1
10.128.1.2 is NODE2
10.128.1.254 is the VIP (and the VIP is the designated DNS server at the endpoints)
Using this syntax, we see the endpoint is assigned like this:
*NIX terminal shows us this:
% cat /etc/resolv.conf |grep nameserver
nameserver 10.128.1.254
Similarly in Windows, we see this:
C:\Users\David>ipconfig /all | find "DNS Servers"
DNS Servers . . . . . . . . . . . : 10.128.1.254
Notice that the DHCP-assigned resolver is the VIP, yet all 3 of them offer DNS answers from macOS/Linux:
Let’s start by doing the query to the one and only DHCP-assigned resolver:
% dig captive.apple.com +short
17.253.119.202
17.253.119.201
For good measure, let’s check directly with the real nodes behind the VIP:
% dig @10.128.1.1 captive.apple.com +short
17.253.119.202
17.253.119.201
% dig @10.128.1.2 captive.apple.com +short
17.253.119.201
17.253.119.202
And the same goes for Windows:
C:\Users\David>nslookup dns.msftncsi.com
Server: gateway.hq.anycorp.io
Address: 10.128.1.254
Non-authoritative answer:
Name: dns.msftncsi.com
Address: 131.107.255.255
C:\Users\David>nslookup dns.msftncsi.com 10.128.1.1
Server: gateway1.hq.anycorp.io
Address: 10.128.1.1
Non-authoritative answer:
Name: dns.msftncsi.com
Address: 131.107.255.255
C:\Users\David>nslookup dns.msftncsi.com 10.128.1.2
Server: gateway2.hq.anycorp.io
Address: 10.128.1.2
Non-authoritative answer:
Name: dns.msftncsi.com
Address: 131.107.255.255
Since all of them responded as expected, we have a 30-point score so far.
Active Directory domain answers are available from multiple AD DNS servers
An important design element in the enterprise is that endpoints never reference Active Directory DNS directly. Instead, designated resolvers, know to consult AD DNS only for domains where AD DNS is authoritative. With that understanding, here’s how this check can be validated, depending on the environment:
We use an SRV query to validate that such records exist and are answered via our DHCP-assigned single DNS server:
% dig SRV _ldap._tcp.dc._msdcs.hq.anycorp.io
; <<>> DiG 9.18.16 <<>> SRV @10.128.1.254 _ldap._tcp.dc._msdcs.hq.anycorp.io
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 37719
;; flags: qr aa rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 3
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 1232
; COOKIE: 2f05f36be2bd44330abc73e5e534efff2afbb8c4f18200d945da8eab9aac760a (good)
;; QUESTION SECTION:
;_ldap._tcp.dc._msdcs.hq.anycorp.io. IN SRV
;; ANSWER SECTION:
_ldap._tcp.dc._msdcs.hq.anycorp.io. 600 IN SRV 0 100 389 dc1.hq.anycorp.io.
_ldap._tcp.dc._msdcs.hq.anycorp.io. 600 IN SRV 0 100 389 dc2.hq.anycorp.io.
;; ADDITIONAL SECTION:
dc1.hq.anycorp.io. 3600 IN A 10.128.3.201
dc2.hq.anycorp.io. 3600 IN A 10.128.3.202
;; Query time: 1 msec
;; SERVER: 10.128.1.254#53(10.128.1.254) (UDP)
;; WHEN: Sat Sep 28 14:43:36 EDT 2024
;; MSG SIZE rcvd: 231
The important observation is to see if both AD servers were queried for the DNS query itself, which is captured in the logs of adam:ONE and/or centralized SIEM, notice that the query was forwarded to two (2) domain controllers:
%: grep "_ldap._tcp.dc._msdcs.hq.anycorp.io" /var/log/anmuscle.log | grep “DNS>”
I 28/9 14:43:36.744308 67114 DNS> 10.128.2.100@54699 UDP4 _ldap._tcp.dc._msdcs.hq.anycorp.io SRV | 10.128.3.201@53 [timeout 5000]
I 28/9 14:43:36.744418 67114 DNS> 10.128.2.100@54699 UDP4 _ldap._tcp.dc._msdcs.hq.anycorp.io SRV | 10.128.3.202@53 [timeout 5000]
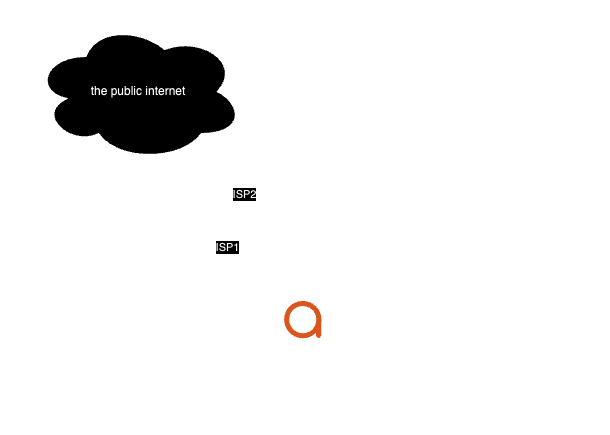
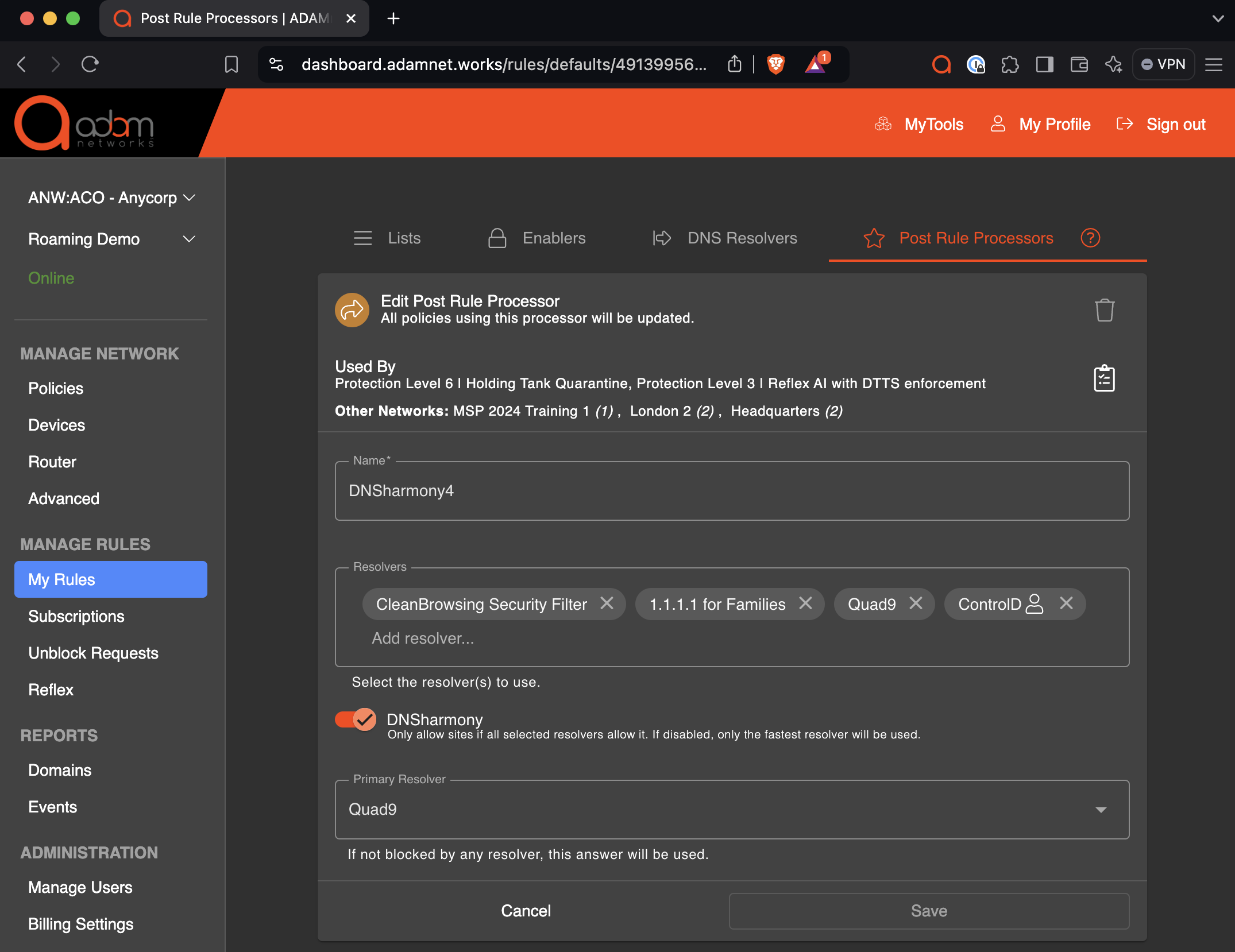
Multiple resolver sets are used with DNSharmony
In DNSharmony, multiple resolver sets can be created and then used to harmonize (if any protective resolver blocks an FQDN, the answer is blocked). Here’s an example:
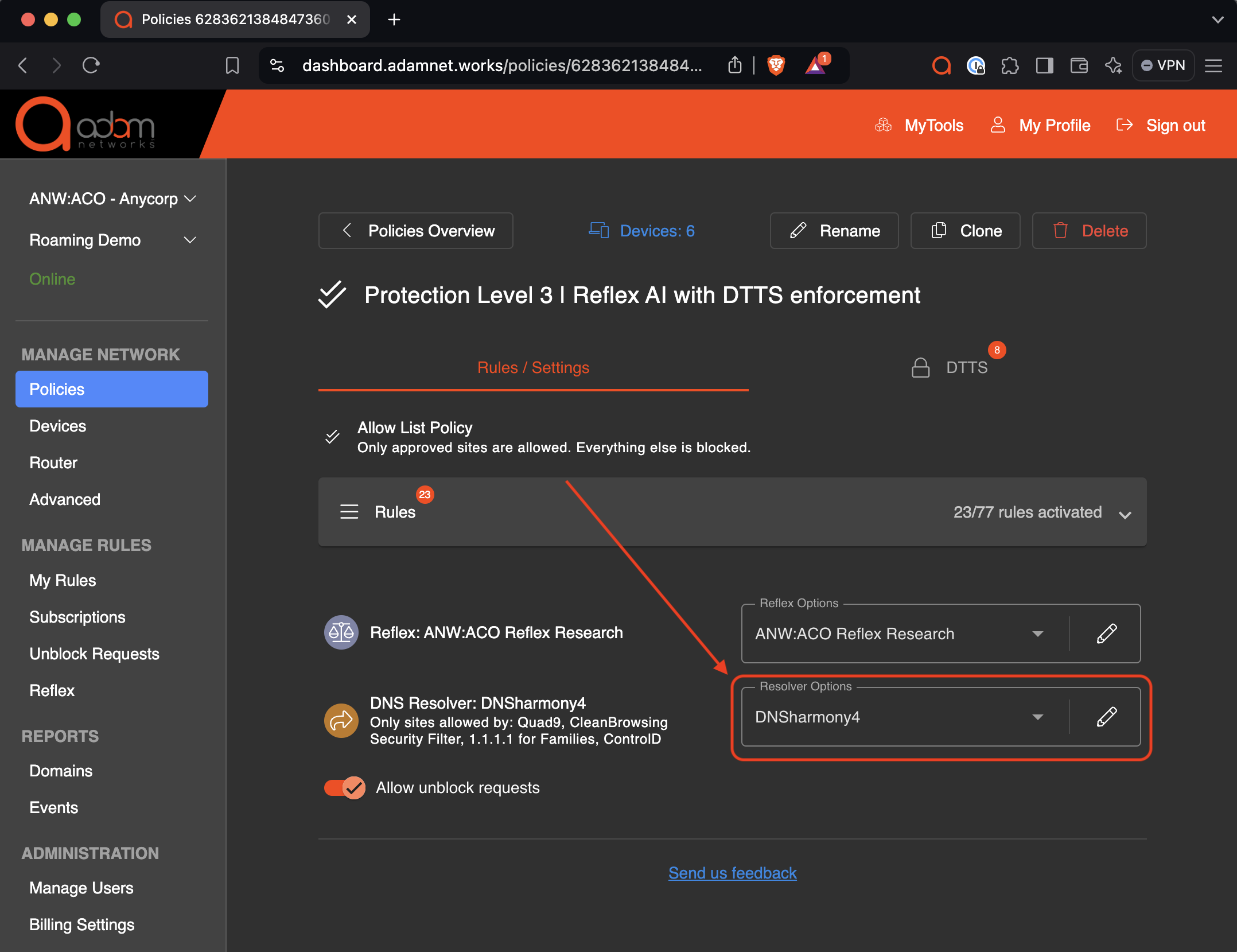
Here’s how it is then applied to the policy itself:
Multiple ISPs on separate circuits
Let’s use VyOS as an example where a load-balanced WAN setup can be verified:
vyos@vyos:~$ show wan-load-balance
Interface: eth0
Status: failed
Last Status Change: Tue Sep 26 20:12:19 2024
-Test: ping Target:
Last Interface Success: 55s
Last Interface Failure: 0s
# Interface Failure(s): 5
Interface: eth1
Status: active
Last Status Change: Tue Sep 26 20:06:42 2024
+Test: ping Target:
Last Interface Success: 0s
Last Interface Failure: 6m26s
# Interface Failure(s): 0
Using the above example, WAN1 runs over eth0 and WAN2 runs over eth1, and as long as the upstream resolver pairs are split-routed, no DNS outage is experienced.
Resolver pairs are split between ISP connections for best resilience
When more than one ISP is being used, the DNS resolver sets should be distributed also (in most cases). Here’s an example of how they are split between two ISPs for the same resolver set (9.9.9.9 first):
My traceroute [v0.95]
gateway1.hq.anycorp.io (10.0.0.206) -> 9.9.9.9 (9.9.9.9) 2024-10-02T15:40:38-0400
Keys: Help Display mode Restart statistics Order of fields quit
Packets Pings
Host Loss% Snt Last Avg Best Wrst StDev
1. 10.0.0.1 0.0% 4 1.3 1.4 1.1 1.8 0.3
2. pool-99-242-108-1.cpe.net.cable.rogers.com 0.0% 3 16.7 16.7 16.6 16.8 0.1
3. 8079-dgw02.lndn.rmgt.net.rogers.com 0.0% 3 14.8 15.7 14.8 17.0 1.1
4. unallocated-static.rogers.com 0.0% 3 16.5 17.6 16.5 18.8 1.2
5. 209.148.235.214 0.0% 3 18.2 21.5 18.2 26.8 4.7
6. ae58.bar3.Toronto1.Level3.net 0.0% 3 34.7 33.4 31.1 34.7 2.0
7. ae2.3601.ear1.NewYork6.net.lumen.tech 50.0% 3 31.8 31.8 31.8 31.8 0.0
8. 42-3356-nyc.sp.lumen.tech 0.0% 3 34.5 35.0 34.5 36.0 0.8
9. dns9.quad9.net 0.0% 3 36.2 34.3 32.1 36.2 2.1
Second, let’s review the path to 149.112.112.112:
My traceroute [v0.95]
gateway1.hq1.anycorp.io (10.0.3.201) -> 149.112.112.112 (149.112.12024-10-02T15:51:03-0400
Keys: Help Display mode Restart statistics Order of fields quit
Packets Pings
Host Loss% Snt Last Avg Best Wrst StDev
1. 10.0.3.1 0.0% 7 0.4 0.3 0.3 0.4 0.0
2. 216.181.8.129 0.0% 7 13.2 11.5 7.9 13.9 2.3
3. 216.181.206.66 0.0% 6 15.5 19.8 15.2 29.2 5.8
4. 216.181.209.65 0.0% 6 12.7 16.4 11.8 20.8 3.6
5. 216.254.130.174 0.0% 6 15.8 16.6 14.4 20.6 2.1
6. xe-1-1-1-991.ipr02.mtlcnds.distributel.net 0.0% 6 15.1 14.8 11.7 16.7 2.1
7. 206.80.255.6 0.0% 6 17.0 16.3 11.5 19.8 2.7
8. equinixmetal-b.ip4.torontointernetxchange.net 0.0% 6 20.0 17.4 15.5 20.0 1.7
9. (waiting for reply)
10. (waiting for reply)
11. paz1.qyyz2 0.0% 6 16.1 16.6 14.8 17.8 1.1
12. dns.quad9.net 0.0% 6 15.5 15.3 13.8 18.1 1.6
Standard network monitor settings
Finally, if and when such redundancies fail at any stage, there must be a monitoring instance that alerts the network engineering team to a failure. What better way to test than to repeatedly confirm that the DNS services are running on each node.
For this reason, our managed clients have a listener on localhost which can then be systematically monitored for domain mytools.management that will resolve to the LAN interface from which it was queried, and any non-answer, or public IP answer means the DNS services are failing. This can be done by integrating tools such as zabbix or cronitor alerts.
Final notes
One more feature of adam:ONE, the on-premise caching resolver service is an automatic back-off for non-responsive resolvers. This allows for redundancy without sacrificing performance. Most importantly, this facilitates resilience even in typical supply-chain problems (ISPs, public resolvers, etc).
Update
UPDATE: including a diagram that shows a sample of a fully-resiient network that meets all the requirements above: